
We help connect verifiable, real-economy data to the financial economy,
so decision-makers can trust their investments in our Net Zero Future.
We enable you to connect with organizations you trust, using Trust Frameworks.
At Icebreaker One (IB1) we help groups collaboratively design market rules for data sharing, and then implement them using Trust Frameworks (which IB1 operates on behalf of stakeholders). Trust Frameworks are a core component of Data Sharing Infrastructure that enable data flow to operate at national and international scales.
To facilitate this IB1 is an independent, non-partisan, non-profit.

(click to enlarge)
Trust Frameworks should do as little as possible
(to balance the building of trust, while reducing transactional friction)
Designing our Data Sharing Infrastructure
Data sharing at scale requires the separation of ‘the data’ from its governance and the technology used to host and transfer it. In a Trust Framework (TF) market architecture, the number of ‘places’ where the data is used is decentralised and distributed (with supporting legal, security and technical rules) and made available in a peer-to-peer architecture.
The approach has three elements:
- Co-design of the rules for data sharing (both technical and non-technical)
- Implementation of the rules in a machine-compatible and enforceable manner
- Market access via verified, permission-based trust to enable data to be shared directly between organisations.
- From a data user’s perspective, they want to know ‘can I find data, access it and use it for this purpose?‘
- From a data provider’s perspective, they want to know ‘can users find my data, access and use it with the right permissions?‘.
- Both want to know ‘can we [legally] trust each other, and what do we do if something goes wrong?‘
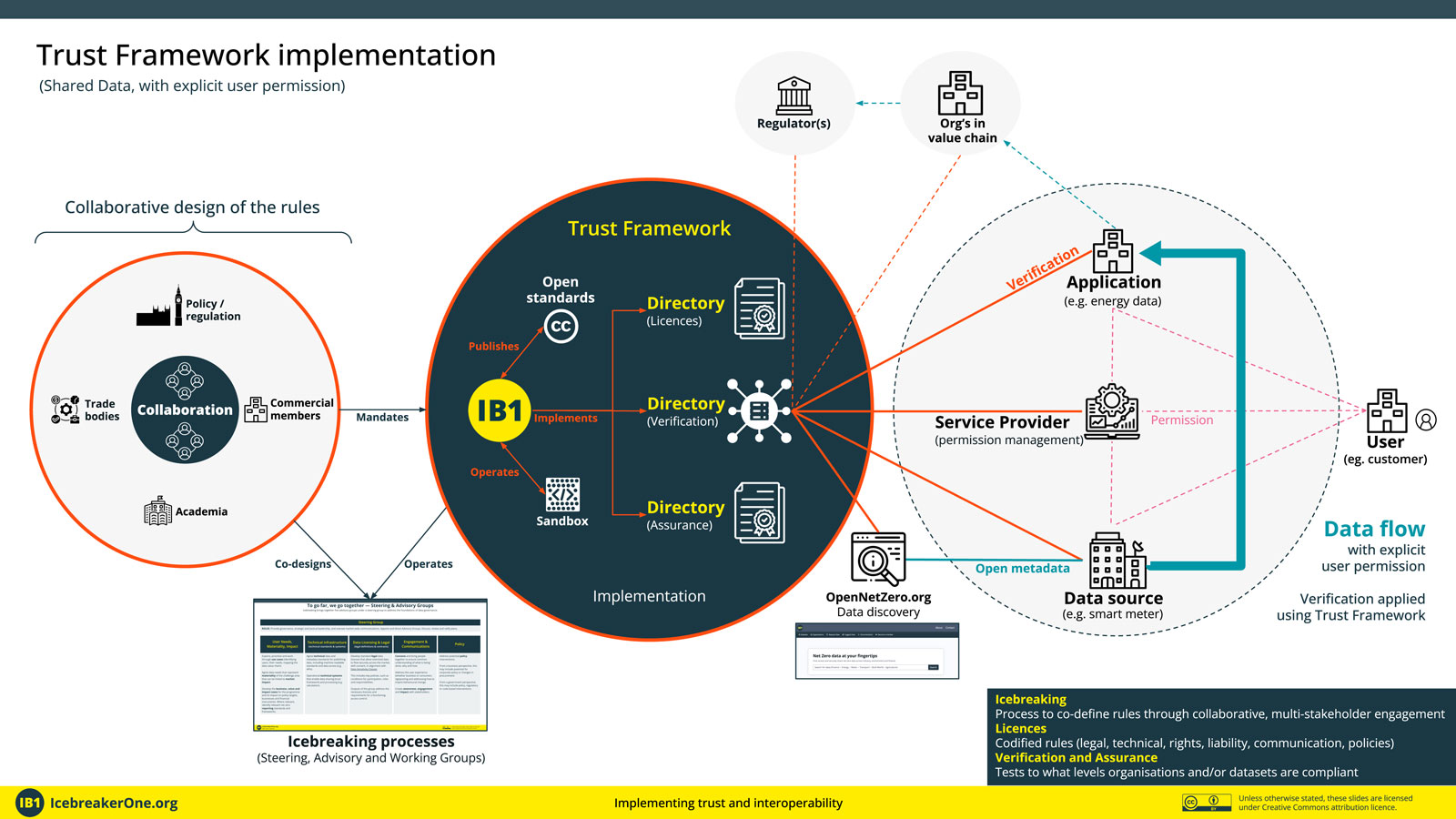
In the diagram above,
- On the left, humans come together to define rules (rights, standards, policies)
- In the middle, those rules are codified (legally & technically) into a Trust Framework
- On the right, organisations (and their machines) can check they have agreed to the rules
In this diagram, we illustrate that this can also include the explicit permission of an end user (permission is aligned with consumer ‘consent’ used in Open Banking). The end user doesn’t need to be in the Trust Framework but they do want to know the organisations handling their data (e.g. software applications) are in it – so they can have trust in the processes and mechanisms of redress if needed. The Trust Framework also supports two other models of implementation: where data rights are predefined and don’t need granular user permission, and where usage rights are waived using an open data license. To summarise, there are three types of use-case:
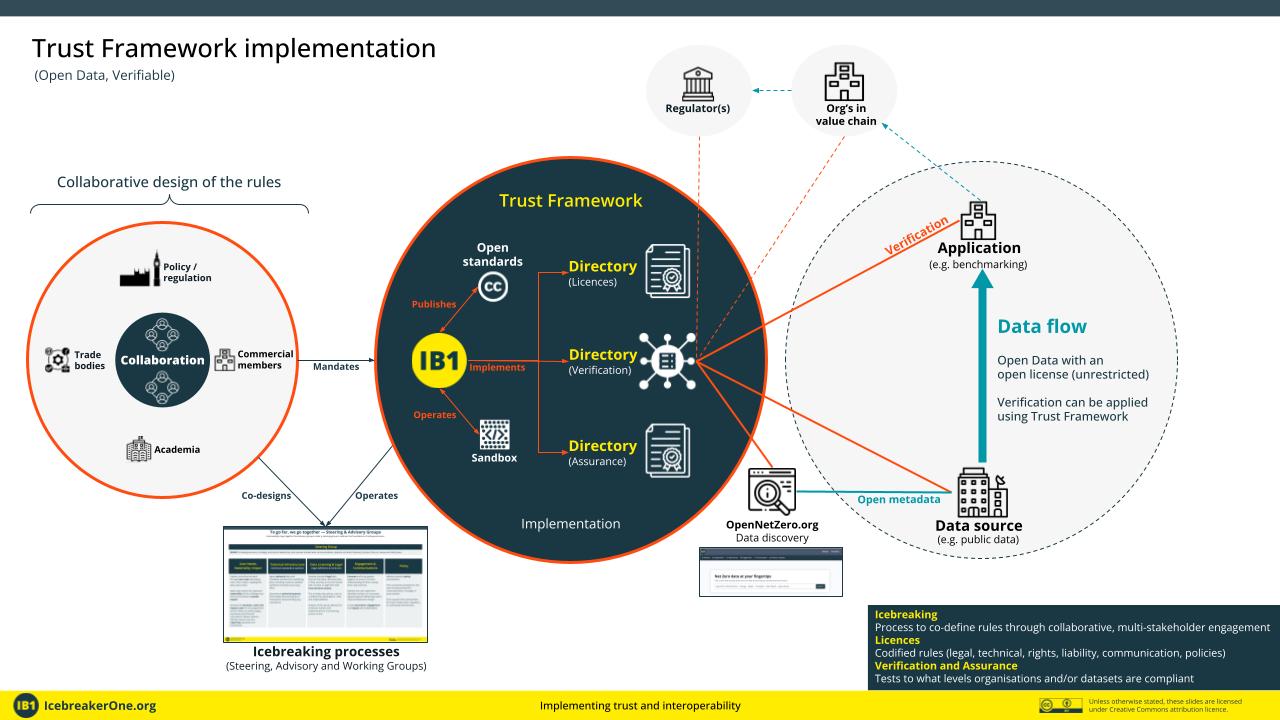
- Open data (verifiable)
- Shared data (without granular permission)
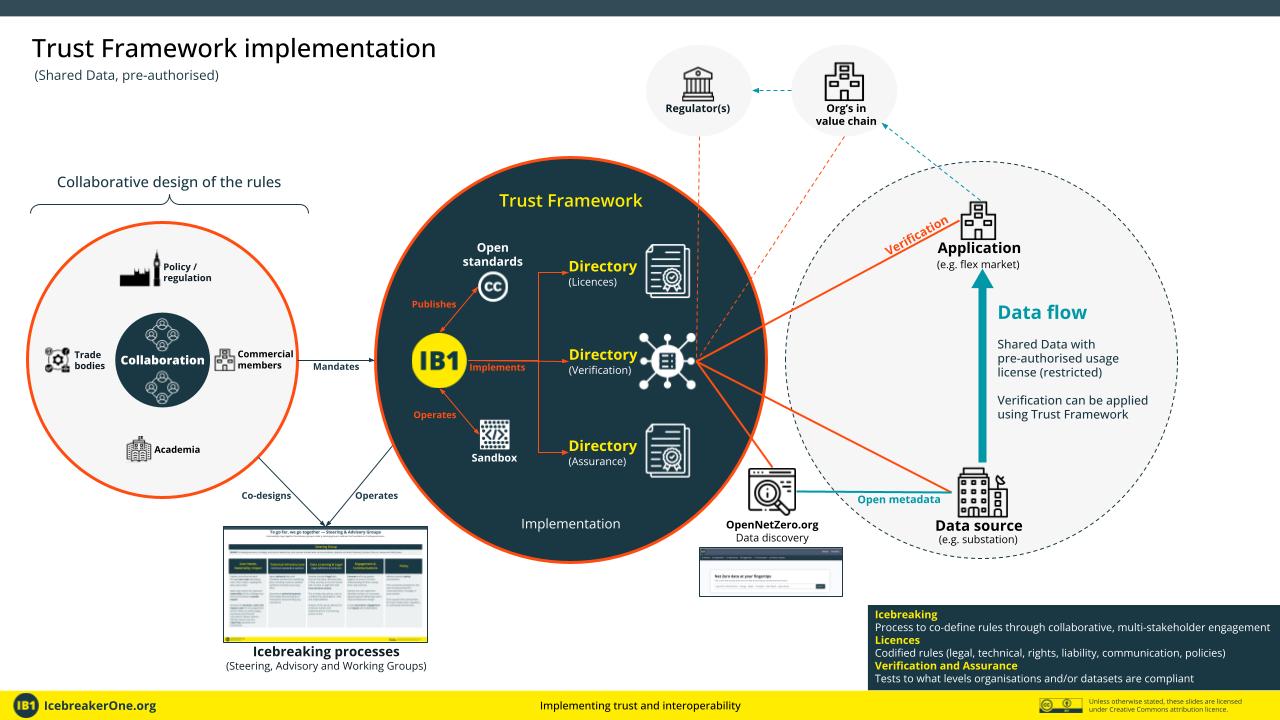
- Shared data (with granular permission)
A critical design feature of a Trust Framework is that it does as little as possible. It doesn’t define the rules, nor does it touch the underlying data, or know who the end users are. It just verifies that rules have been agreed and can enable their enforcement.
Below is the implementation for verifiable Open Data.
And for pre-authorised Shared Data
Example
By way of example, in Open Banking, a customer’s current account data can be shared directly from their online bank to an online accounting provider to automate the creation of a tax return. The bank and accounting solution are both in a Trust Framework which protects both of them, and the end customer. It is co-designed by industry and regulators and is implemented via an independent non-profit body. This independent body operates the Trust Framework. It never touches the user’s data, nor knows who the user is. It manages the trust relationship between the market actors and, as a regulated sector can aid enforcement (e.g. excluding bad actors from the ecosystem).

Icebreaker One implementations
In collaboration with its members, Icebreaker One creates Trust Frameworks that enable easier, secure and trusted data sharing to help deliver our net zero future. By enabling greater discoverability and interoperability of data while reducing friction associated with sharing data, Trust Frameworks accelerate innovation by unlocking access to currently under-utilised data at market scale.
To enable pre-authorised access to data, Trust Frameworks include both verification and assurance services.
The rules that are codified in Trust Frameworks should be built on five principles They should be:
- Cohesive — common rules across markets
- Interoperable — common processes, frameworks, connections
- Legal — common frameworks for data rights, liability, redress
- Controlled — common, rights-based permission management for access to data
- Universal — open to the whole market
There are other ways of sharing data, but few that scale to whole-of-market, national and international scales, using systems that exist today, are ubiquitous and cost-effective.
How can Trust Frameworks be governed?
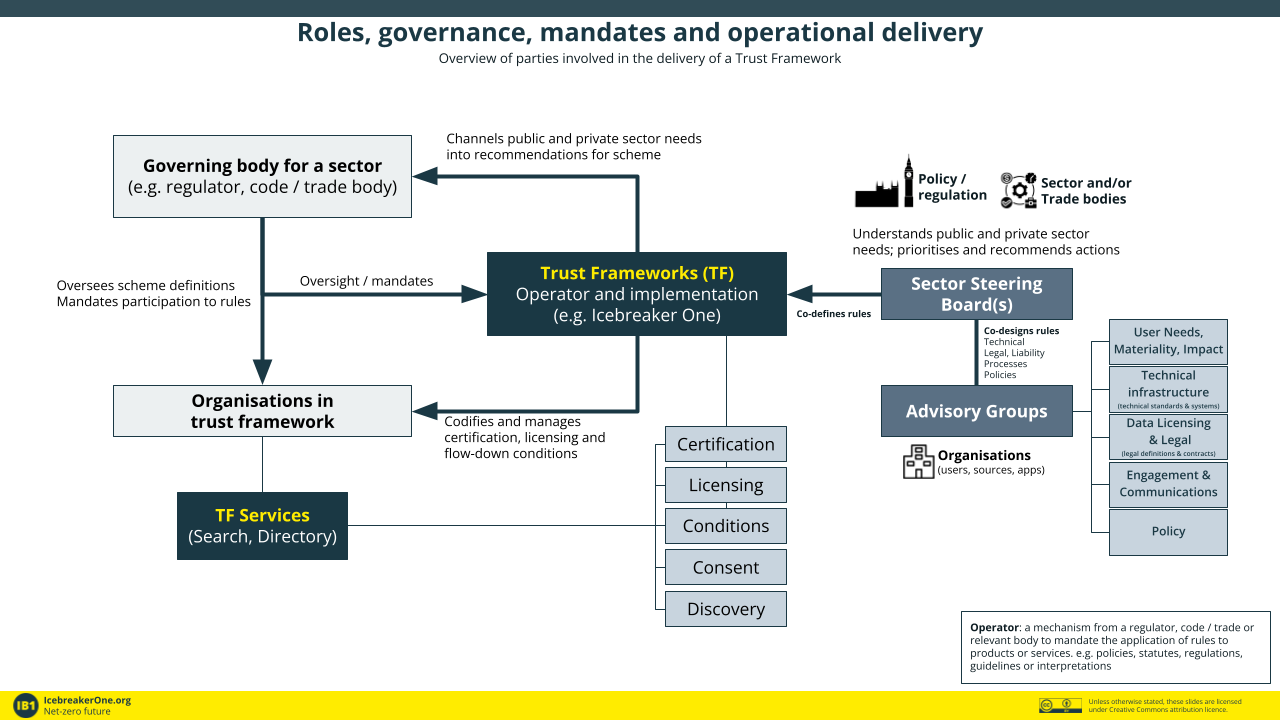
The needs and rules of the ecosystem and market are not defined by a Trust Framework operator, they are implemented by it. Different organisations have different views and needs and these will continue to expand over time.
The Trust Framework must not store or ‘touch’ the actual data. They provide a way of enabling organisations (and machines) to trust that other organisations have agreed to the rules, and can help enforce those rules.
We have identified five pillars of development to enable the cohesive delivery of Trust Frameworks:
- User needs, impact
- Technical infrastructure
- Data licensing & legal
- Engagement & communications
- Policy
For more details on this, please see our Icebreaking process.
Why is a Trust Framework for data sharing needed?
Huge quantities of data are being generated from our energy systems, financial systems, our built world and our environment. To fully exploit its value, we need to connect data to those who need it. We want to reduce the friction of finding, accessing, and using both commercial and non-commercial data to enable better decision-making to achieve net zero.
This isn’t a problem that needs new technology. Many attempts to consolidate data—new databases and portals—struggle to scale. Our economic and infrastructure systems are being digitalized in a decentralised and distributed way (e.g. TF’s are based on what works and can be contract-based and/or API-based. They do not require distributed ledgers/etc). There is no ‘centre’ in a system like this: we need to connect data, not collect it. Trust Frameworks enable this by setting the rules of the road and addressing risks and concerns that prevent the sharing and use of data.
According to a UN and World Bank report, investment in scalable, interoperable data ecosystems yields a 32x return on investment. Further, the lack of trusted data flow is leading to poor decisions that make it more risky and difficult to quantify and invest in the transition to net zero.
What does it do?
The Trust Framework is a very ‘thin’ layer. It assures that (a) organisations are who they say they are; (b) permission (similar to consumer-based consent in Open Banking) is given to share data with the pre-agreed rules; and (c) enables that permission to be linked to rules for licensing, liability transfer, legal and operational processes (e.g. open standards for data, APIs, etc).
To enable pre-authorised access to data, the Trust Framework will include verification and assurance services for organisations who wish to share, access and use data. Tiers for verification and assurance include verification and assurance at both organisational and dataset levels:
- Organisational checks: for example, confirming the organisation is a legal company entity with an Icebreaker One Membership Agreement; is signed up to the Information Commissioners Office. Higher levels will include KYC checks.
- Organisational policy alignment and/or compliance with policies and standards: for example, alignment with regulatory guidance such as Open Data Best Practices; Published data strategy; Published Net Zero related reports (e.g. TCFD, PCAF)
- Dataset alignment and/or compliance: for example, license checks for Open Data licenses, machine-readable meta-data; usage of Open Data Certificates; alignment with Data Sensitivity Classes; compliance with IB1 Trust Framework License Agreements.
What sectors need Trust Frameworks?
The architecture of Trust Frameworks are sector-agnostic. They can be implemented for any one sector and across sectors (for example, developing hydropower projects depends on collaboration, and data sharing, between the energy and water sectors). However, as each sector has its own specific needs, sector-specific Trust Frameworks will be needed to agree upon and operationalise sector-specific rules depending on commercial, regulatory, and technical needs. We are developing the first Trust Framework for the energy sector – Open Energy – and are keen to work with partners to do the same in other areas of the economy.
How can we contribute to, and benefit from, Trust Frameworks?
To contribute to the development of the fundamental Trust Framework principle, or to the implementation of sector-specific Trust Framework implementations, become an Icebreaker One Member.
Roadmap to a connected data strategy
Three steps to deliver a cohesive and interoperable data infrastructure:
1. Design for search — the foundation for discovery and access
Data must be usable by machines, not just humans. Policies must mandate that data be machine-readable in order that it may be collected and used in an efficient manner. As important is the ability to discover that the data exists, what it is, where it is from, and how it may be used. This ‘metadata’ is a priority to make available so that data may be found and information about it accessed. Policies must mandate the production of meta-data that will aid discovery.
This first priority is independent of the specifics of any taxonomy, ontology or other structural design. Such designs are numerous and domain-specific.
2. Address data licensing policies — the foundation of access and usage
Licensing can determine how data may be used. To unlock the value of Priority 1, policies must mandate the publishing of licenses (or usage rules) as metadata under an open license. This is essential to enable large-scale, many-to-many discovery that data exists in a usable form.
Policies should mandate the publishing of any non-sensitive data under an Open license (this mirrors the open-by-default policies of many countries). Policies should mandate the publishing of sensitive data using a Trust Framework.
3. Address data governance — the foundation of open markets
Data increases in value the more it is connected. A focus on systemic cohesion and interoperability reduces the burden of sharing by creating common rules and frameworks for sharing that address good data governance. It ensures data is used appropriately for the purposes intended, addressing questions of security, liability and redress. Organisations must address their own data governance and should aim toward common rules and processes to increase adoption, reduce costs and simplify interactions between data suppliers and data users.